curl is a super popular command line tool for downloading files over the network via various network protocols like HTTP or FTP. It also supports submitting GET/POST requests via HTTP, making it very useful for API development and debugging.
curl is based on a libcurl library, part of the same project, which makes it more suitable for use in programming various applications.
Test if Webpage Exists
Simply specify a URL and curl will attempt a download:
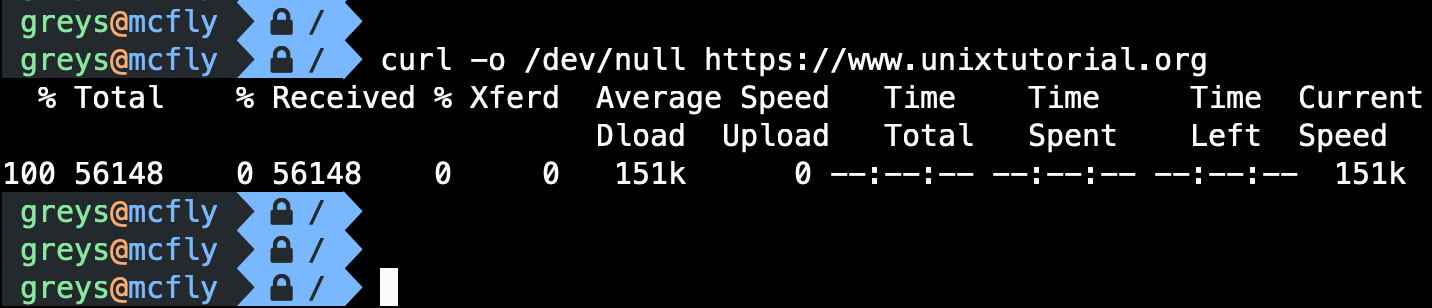
$curl -o /dev/null https://www.unixtutorial.org
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 56148 0 56148 0 0 151k 0 --:--:-- --:--:-- --:--:-- 151k
In this example, we’re using the -o (output) option to redirect output (page contents) into /dev/null - we basically discard the contents as we’re not interested in it just yet.
Download File or Webpage into a File
In this example, we’re using the same -o option but specify a filename instead of /dev/null - thus making curl command save the URL content into a file named /tmp/webpage.html:
$curl -o /tmp/webpage.html https://www.unixtutorial.org
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 56148 0 56148 0 0 151k 0 --:--:-- --:--:-- --:--:-- 151k
If we check now, /tmp/webpage.html file exists and contains whatever my main webpage did at the time of the download:
I'm a principal consultant with Tech Stack Solutions. I help with cloud architectrure, AWS deployments and automated management of Unix/Linux infrastructure. Get in touch!
 curl command
curl command
{kind=link}