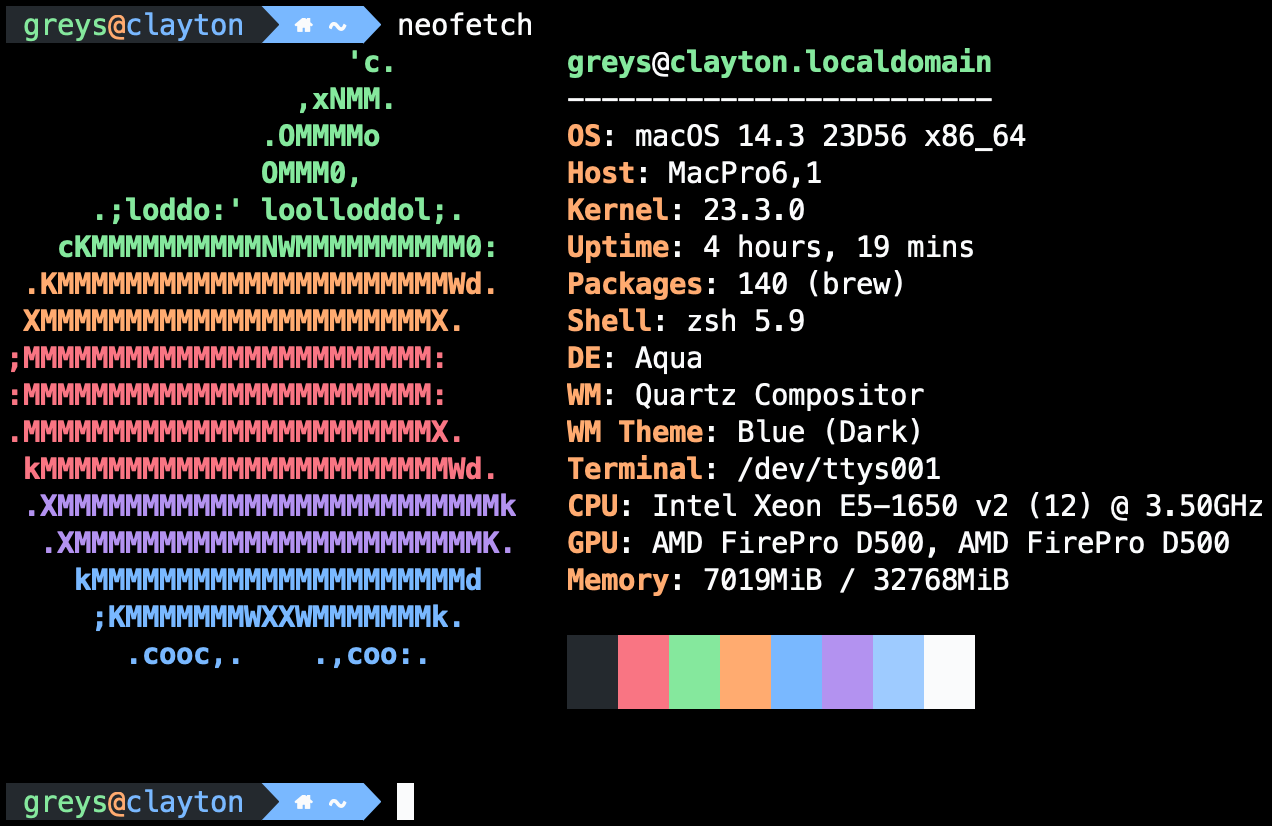
 Mac Pro 2013 - macOS Sonoma
Mac Pro 2013 - macOS Sonoma
Yes, the year is 2024 and Mac Pro 2013 is now more than 10 years old, but many models are still in perfect working order and pack quite a punch for something this old.
The model I got comes with 6-core Xeon CPU and 32GB RAM and 512GB SSD. I think it has 6 thunderbolt connections and 4 USB ones, not to mention two Gigabit network interfaces and HDMI. It’s an old system so HDMI only supports 30Mhz for 4K, but thunderbolt connection should support 60Mhz.
If I really want to, I can upgrade it to 64GB RAM or even a much better 12-core CPU - both upgrades seem to be overkill but also sound like quite fun projects (and spares for such an old system are really cheap these days).
As always, initial post-config is done using Ansible and homebrew.
 MacBook Pro 14” - M2
MacBook Pro 14” - M2
 macOS 13 - Ventura
macOS 13 - Ventura
 Video: Testing TCP Connections with curl
Video: Testing TCP Connections with curl
 VMware Workstation Pro
VMware Workstation Pro
 VMware Workstation won’t install unless you delete VMware Player
VMware Workstation won’t install unless you delete VMware Player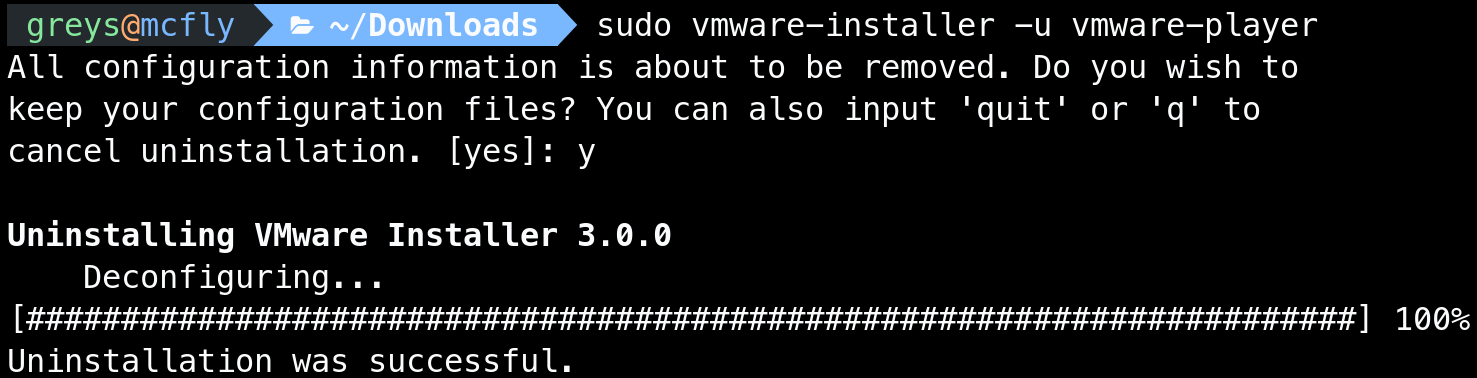 VMware Player uninstall
VMware Player uninstall VMware Workstation install in Linux Mint
VMware Workstation install in Linux Mint curl –insecure example
curl –insecure example